NGSIToPostgreSQL
Content:
- Functionality
- Administration guide
Functionality
NGSIToPostgreSQLis a processor designed to persist NGSI-like context data events within a
PostgreSQL server. Usually, such a context data is notified by a
Context Boker (Orion Context Broker,Orion-LD Context Broker,Scorpio Broker ) instance, but could be any other system speaking
the NGSI language.
Independently of the data generator, NGSI context data is always transformed into internal NGSIEvent objects at Draco
sources. In the end, the information within these events must be mapped into specific PostgreSQL data structures.
Next sections will explain this in detail.
Mapping NGSI events to NGSIEvent objects
Notified NGSI events (containing context data) are transformed into NGSIEvent objects (for each context element a
NGSIEvent is created; such an event is a mix of certain headers and a ContextElement object), independently of the
NGSI data generator or the final backend where it is persisted.
This is done at the Draco-ngsi Http listeners (in NiFi, processors) thanks to
NGSIRestHandler. Once translated, the data (now, as NGSIEvent objects) is put into the
internal channels for future consumption (see next section).
Managing NGSIv2 notifications
Mapping NGSIEvents to PostgreSQL data structures
PostgreSQL organizes the data in schemas inside a database that contain tables of data rows. Such organization is
exploited by NGSIToPostgreSQL each time a NGSIEvent is going to be persisted.
PostgreSQL databases naming conventions
Previous to any operation with PostgreSQL you need to create the database to be used.
It must be said
PostgreSQL only accepts
alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending
on the enable_encoding configuration parameter.
PostgreSQL databases name length is limited to 63 characters.
PostgreSQL schemas naming conventions
A schema named as the notified fiware-service header value (or, in absence of such a header, the defaulted value for
the FIWARE service) is created (if not existing yet).
It must be said
PostgreSQL only accepts
alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending
on the enable_encoding configuration parameter.
PostgreSQL schemas name length is limited to 63 characters.
PostgreSQL tables naming conventions
The name of these tables depends on the configured data model (see the Configuration section for more details):
- Data model by service path (
data_model=dm-by-service-path). As the data model name denotes, the notified FIWARE service path (or the configured one as default inNGSIRestHandler) is used as the name of the table. This allows the data about all the NGSI entities belonging to the same service path is stored in this unique table. The only constraint regarding this data model is the FIWARE service path cannot be the root one (/). - Data model by entity (
data_model=dm-by-entity). For each entity, the notified/default FIWARE service path is concatenated to the notified entity ID and type in order to compose the table name. If the FIWARE service path is the root one (/) then only the entity ID and type are concatenated.
It must be said
PostgreSQL only accepts
alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending
on the enable_encoding configuration parameter.
PostgreSQL tables name length is limited to 63 characters.
The following table summarizes the table name composition (old encoding):
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
N/A | <entityId>_<entityType> |
/<svcPath> |
<svcPath> |
<svcPath>_<entityId>_<entityType> |
Using the new encoding:
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
x002f |
x002fxffff<entityId>xffff<entityType> |
/<svcPath> |
x002f<svcPath> |
x002f<svcPath>xffff<entityId>xffff<entityType> |
Please observe the concatenation of entity ID and type is already given in the notified_entities/grouped_entities
header values (depending on using or not the grouping rules, see the Configuration section for more
details) within the NGSIEvent.
Row-like storing
Regarding the specific data stored within the above table, if attr_persistence parameter is set to row (default
storing mode) then the notified data is stored attribute by attribute, composing an insert for each one of them. Each
insert contains the following fields:
recvTimeTs: UTC timestamp expressed in miliseconds.recvTime: UTC timestamp in human-redable format (ISO 8601).fiwareServicePath: Notified fiware-servicePath, or the default configured one if not notified.entityId: Notified entity identifier.entityType: Notified entity type.attrName: Notified attribute name.attrType: Notified attribute type.attrValue: In its simplest form, this value is just a string, but since Orion 0.11.0 it can be Json object or Json array.attrMd: It contains a string serialization of the metadata array for the attribute in Json (if the attribute hasn't metadata, an empty array[]is inserted).
Column-like storing
Regarding the specific data stored within the above table, if attr_persistence parameter is set to column then a
single line is composed for the whole notified entity, containing the following fields:
recvTime: UTC timestamp in human-redable format (ISO 8601).fiwareServicePath: The notified one or the default one.entityId: Notified entity identifier.entityType: Notified entity type.- For each notified attribute, a field named as the attribute is considered. This field will store the attribute values along the time.
- For each notified attribute, a field named as the concatenation of the attribute name and
_mdis considered. This field will store the attribute's metadata values along the time.
Example
NGSIEvent
Assuming the following NGSIEvent is created from a notified NGSI context data (the code below is an object
representation, not any real data format):
ngsi-event={
headers={
content-type=application/json,
timestamp=1429535775,
transactionId=1429535775-308-0000000000,
correlationId=1429535775-308-0000000000,
fiware-service=vehicles,
fiware-servicepath=/4wheels,
<grouping_rules_interceptor_headers>,
<name_mappings_interceptor_headers>
},
body={
entityId=car1,
entityType=car,
attributes=[
{
attrName=speed,
attrType=float,
attrValue=112.9
},
{
attrName=oil_level,
attrType=float,
attrValue=74.6
}
]
}
}
Database, schema and table names
The PostgreSQL database name will be of the user's choice.
The PostgreSQL schema will always be vehicles.
The PostgreSQL table names will be, depending on the configured data model, the following ones (old encoding):
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
N/A | car1_car |
/4wheels |
4wheels |
4wheels_car1_car |
Using the new encoding:
| FIWARE service path | dm-by-service-path |
dm-by-entity |
|---|---|---|
/ |
x002f | x002fxffffcar1xffffcar |
/4wheels |
x002f4wheels |
x002f4wheelsxffffcar1xffffcar |
Row-like storing
Assuming attr_persistence=row as configuration parameters, then NGSIToPostgreSQL will persist the data within the
body as:
$ psql -U myuser
psql (9.5.0)
Type "help" for help.
postgres-# \c my-database
my-database# \dn
List of schemas
Name | Owner
----------+----------
vehicles | postgres
public | postgres
(2 rows)
my-database=# \dt vehicles.*
List of relations
Schema | Name | Type | Owner
----------+-------------------+-------+----------
vehicles | 4wheels_car1_car | table | postgres
(1 row)
postgresql> select * from vehicles.4wheels_car1_car;
+------------+----------------------------+-------------------+----------+------------+-------------+-----------+-----------+--------+
| recvTimeTs | recvTime | fiwareServicePath | entityId | entityType | attrName | attrType | attrValue | attrMd |
+------------+----------------------------+-------------------+----------+------------+-------------+-----------+-----------+--------+
| 1429535775 | 2015-04-20T12:13:22.41.124 | 4wheels | car1 | car | speed | float | 112.9 | [] |
| 1429535775 | 2015-04-20T12:13:22.41.124 | 4wheels | car1 | car | oil_level | float | 74.6 | [] |
+------------+----------------------------+-------------------+----------+------------+-------------+-----------+-----------+--------+
2 row in set (0.00 sec)
Column-like storing
If attr_persistence=column then NGSIToPostgreSQL will persist the data within the body as:
postgresql> select * from 4wheels_car1_car;
+------------+---------------------------+-------------------+----------+------------+-------+----------+-----------+--------------+
| recvTimeTs | recvTime | fiwareServicePath | entityId | entityType | speed | speed_md | oil_level | oil_level_md |
+------------+---------------------------+-------------------+----------+------------+-------+----------+-----------+--------------+
| 1429535775 |2015-04-20T12:13:22.41.124 | 4wheels | car1 | car | 112.9 | [] | 74.6 | [] |
+------------+---------------------------+-------------------+----------+------------+-------+----------+-----------+--------------+
1 row in set (0.00 sec)
Managing NGSI-LD notifications
Mapping NGSILDEvents to PostgreSQL data structures
PostgreSQL organizes the data in schemas inside a database that contain tables of data rows. Such organization is exploited by NGSILDPostgreSQLSink each time a NGSILDEvent is going to be persisted.
PostgreSQL databases naming conventions
Previous to any operation with PostgreSQL you need to create the database to be used.
It must be said PostgreSQL only accepts alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending on the enable_encoding configuration parameter.
PostgreSQL databases name length is limited to 63 characters.
PostgreSQL schemas naming conventions
A schema named as the notified fiware-service header value (or, in absence of such a header, the defaulted value for the FIWARE service) is created (if not existing yet).
It must be said PostgreSQL only accepts alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending on the enable_encoding configuration parameter.
PostgreSQL schemas name length is limited to 63 characters.
PostgreSQL tables naming conventions
The name of these tables depends on the configured data model (see the Configuration section for more details):
-
Data model by entity (
data_model=dm-by-entity). For each entity, the notified entity ID is collected in order to compose the table name, using (_) for encodigng the special characters presented in the ID fied. -
Data model by entity type (
data_model=dm-by-entity-type). For each entity type, the notified entity type is collected in order to compose the table name. using (_) for encodigng the special characters presented in the ID fied.
It must be said PostgreSQL only accepts alphanumeric characters and the underscore (_). This leads to certain encoding is applied depending on the enable_encoding configuration parameter.
PostgreSQL tables name length is limited to 63 characters.
The following table summarizes the table name composition (old encoding):
dm-by-entity |
dm-by-entity-type |
|---|---|
<entityId> |
<entityType> |
Column-like storing
Regarding the specific data stored within the above table, if attr_persistence parameter is set to column then a single line is composed for the whole notified entity, containing the following fields:
recvTime: UTC timestamp in human-redable format (ISO 8601).entityId: Notified entity identifier.entityType: Notified entity type.- For each notified property/relationship, a field named as the property/relationship is considered. This field will store the property/relationship values along the time, if no unique value is presented, the values will be stored like a JSON string.
Example
NGSILDEvent
Assuming the following NGSILD-event is received from the NGSIRESTHANDLER:
ngsi-notification=
headers={
fiware-service=opniot,
transaction-id=1234567890-0000-1234567890,
correlation-id=1234567890-0000-1234567890,
timestamp=1234567890,
},
{
"id": "urn:ngsi:ld:OffStreetParking:Downtown1",
"type": "OffStreetParking",
"@context": [
"http://example.org/ngsi-ld/parking.jsonld",
"https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context.jsonld"],
"name": {
"type": "Property",
"value": "Downtown One"
},
"availableSpotNumber": {
"type": "Property",
"value": 122,
"observedAt": "2017-07-29T12:05:02Z",
"reliability": {
"type": "Property",
"value": 0.7
},
"providedBy": {
"type": "Relationship",
"object": "urn:ngsi-ld:Camera:C1"
}
},
"totalSpotNumber": {
"type": "Property",
"value": 200
},
"location": {
"type": "GeoProperty",
"value": {
"type": "Point",
"coordinates": [-8.5, 41.2]
}
}
}
Database, schema and table names
The PostgreSQL database name will be of the user's choice.
The PostgreSQL schema will always be openiot.
The PostgreSQL table names will be, depending on the configured data model, the following ones (old encoding):
dm-by-entity |
dm-by-entity-type |
|---|---|
urn_ngsi_ld_offstreetparking_downtown1 |
OffStreetParking |
Assuming attr_persistence=column as configuration parameters, then NGSILDPostgreSQLSink will persist the data within the body as:
Column-like storing
Coming soon.
$ psql -U myuser
psql (9.5.0)
Type "help" for help.
postgres-# \c postgres
postgres=# \dn
List of schemas
Name | Owner
-------------+----------
openiot | postgres
public | postgres
(2 rows)
postgres=# \dt openiot.*
List of relations
Schema | Name | Type | Owner
-------------+----------------------------------------+-------+----------
def_serv_ld | urn_ngsi_ld_offstreetparking_downtown1 | table | postgres
(1 row)
select * from openiot.urn_ngsi_ld_offstreetparking_downtown1;
recvtime | entityid | entitytype | availablespotnumber | availablespotnumber_observedat | availablespotnumber_reliability | availab
lespotnumber_providedby | name | location | totalspotnumber
--------------------------+-------------------+----------------------------------------+------------------+---------------------+--------------------------------+---------------------------------+--------
------------------------+--------------+--------------------------------------------+-----------------
2020-05-12T15:10:39.47Z | urn:ngsi:ld:OffStreetParking:Downtown1 | OffStreetParking | 122 | 2017-07-29T12:05:02Z | 0.7 | urn:ngs
i-ld:Camera:C1 | Downtown One | {"type":"Point","coordinates":[-8.5,41.2]} | 200
2020-05-12T15:27:09.690Z | urn:ngsi:ld:OffStreetParking:Downtown1 | OffStreetParking | 122 | 2017-07-29T12:05:02Z | 0.7 | urn:ngs
i-ld:Camera:C1 | Downtown One | {"type":"Point","coordinates":[-8.5,41.2]} | 200
(2 rows)
Administration guide
Configuration
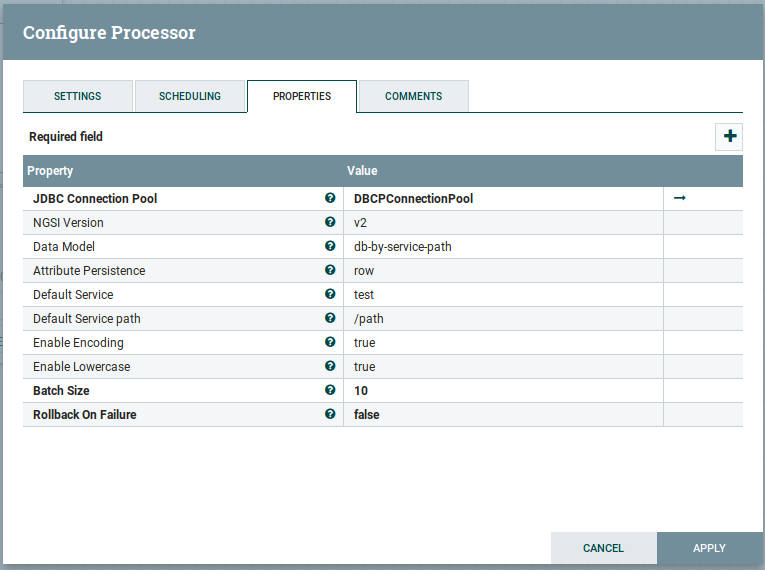
NGSIToPostgreSQL is configured through the following parameters:
| Name | Default Value | Allowable Values | Description |
|---|---|---|---|
| JDBC Connection Pool | no | Controller service for connecting to a specific database engine | |
| NGSI version | v2 | v2, ld | list of supported version of NGSI (v2 and ld) |
| Data Model | db-by-entity | db-by-entity,db-by-entity-type,db-by-service-path | The Data model for creating the tables when an event have been received you can choose between: db-by-service-path or db-by-entity for ngsiv2 and db-by-entity or db-by-entity-type for ngsi-ld, default value is db-by-entity |
| Attribute persistence | row | row, column | The mode of storing the data inside of the table allowable values are row and column for ngsiv2, and only column is allowed for ngsi-ld |
| Default Service | test | In case you dont set the Fiware-Service header in the context broker, this value will be used as Fiware-Service | |
| Default Service path | /path | In case you dont set the Fiware-ServicePath header in the context broker, this value will be used as Fiware-ServicePath | |
| Enable encoding | true | true, false | true applies the new encoding, false applies the old encoding. |
| Enable lowercase | true | true, false | true for creating the Schema and Tables name with lowercase. |
| Batch size | 10 | The preferred number of FlowFiles to put to the database in a single transaction | |
| Rollback on failure | false | true, false | Specify how to handle error. By default (false), if an error occurs while processing a FlowFile, the FlowFile will be routed to 'failure' or 'retry' relationship based on error type, and processor can continue with next FlowFile. Instead, you may want to rollback currently processed FlowFiles and stop further processing immediately. In that case, you can do so by enabling this 'Rollback On Failure' property. If enabled, failed FlowFiles will stay in the input relationship without penalizing it and being processed repeatedly until it gets processed successfully or removed by other means. It is important to set adequate 'Yield Duration' to avoid retrying too frequently. |
A configuration example could be:
Use cases
Use NGSIToPostgreSQL if you are looking for a big database with several tenants. PostgreSQL is bad at having several
databases, but very good at having different schemas.
Important notes
About the table type
The table type configuration parameter, as seen, is a method for direct aggregation of data: by default destination (i.e. all the notifications about the same entity will be stored within the same PostgreSQL table) or by default service-path (i.e. all the notifications about the same service-path will be stored within the same PostgreSQL table).
About the persistence mode
Please observe not always the same number of attributes is notified; this depends on the subscription made to the
NGSI-like sender. This is not a problem for the row persistence mode, since fixed 8-fields data rows are inserted for
each notified attribute. Nevertheless, the column mode may be affected by several data rows of different lengths (in
term of fields). Thus, the column mode is only recommended if your subscription is designed for always sending the
same attributes, event if they were not updated since the last notification.
In addition, when running in column mode, due to the number of notified attributes (and therefore the number of fields
to be written within the Datastore) is unknown by Draco, the table can not be automatically created, and must be
provisioned previously to the Draco execution. That's not the case of the row mode since the number of fields to be
written is always constant, independently of the number of notified attributes.
About batching
As explained in the programmers guide, NGSIToPostgreSQL extends NGSISink, which provides a built-in
mechanism for collecting events from the internal Flume channel. This mechanism allows extending classes have only to
deal with the persistence details of such a batch of events in the final backend.
What is important regarding the batch mechanism is it largely increases the performance of the sink, because the number
of writes is dramatically reduced. Let's see an example, let's assume a batch of 100 NGSIEvents. In the best case, all
these events regard to the same entity, which means all the data within them will be persisted in the same PostgreSQL
table. If processing the events one by one, we would need 100 inserts into PostgreSQL; nevertheless, in this example
only one insert is required. Obviously, not all the events will always regard to the same unique entity, and many
entities may be involved within a batch. But that's not a problem, since several sub-batches of events are created
within a batch, one sub-batch per final destination PostgreSQL table. In the worst case, the whole 100 entities will be
about 100 different entities (100 different PostgreSQL tables), but that will not be the usual scenario. Thus, assuming
a realistic number of 10-15 sub-batches per batch, we are replacing the 100 inserts of the event by event approach with
only 10-15 inserts.
The batch mechanism adds an accumulation timeout to prevent the sink stays in an eternal state of batch building when no new data arrives. If such a timeout is reached, then the batch is persisted as it is.
Regarding the retries of not persisted batches, a couple of parameters is used. On the one hand, a Time-To-Live (TTL) is used, specifing the number of retries Draco will do before definitely dropping the event. On the other hand, a list of retry intervals can be configured. Such a list defines the first retry interval, then se second retry interval, and so on; if the TTL is greater than the length of the list, then the last retry interval is repeated as many times as necessary.
By default, NGSIToPostgreSQL has a configured batch size and batch accumulation timeout of 1 and 30 seconds,
respectively. Nevertheless, as explained above, it is highly recommended to increase at least the batch size for
performance purposes. Which are the optimal values? The size of the batch it is closely related to the transaction size
of the channel the events are got from (it has no sense the first one is greater then the second one), and it depends on
the number of estimated sub-batches as well. The accumulation timeout will depend on how often you want to see new data
in the final storage.
Time zone information
Time zone information is not added in PostgreSQL timestamps since PostgreSQL stores that information as a environment variable. PostgreSQL timestamps are stored in UTC time.
About the encoding
Until version 1.2.0 (included), Draco applied a very simple encoding:
- All non alphanumeric characters were replaced by underscore,
_. - The underscore was used as concatenator character as well.
- The slash,
/, in the FIWARE service paths is ignored.
From version 1.3.0 (included), Draco applies this specific encoding tailored to PostgreSQL data structures:
- Lowercase alphanumeric characters are not encoded.
- Upercase alphanumeric characters are encoded.
- Numeric characters are not encoded.
- Underscore character,
_, is not encoded. - Equals character,
=, is encoded asxffff. - All other characters, including the slash in the FIWARE service paths, are encoded as a
xcharacter followed by the Unicode of the character. - User defined strings composed of a
xcharacter and a Unicode are encoded asxxfollowed by the Unicode. xffffis used as concatenator character.
Despite the old encoding will be deprecated in the future, it is possible to switch the encoding type through the
enable_encoding parameter as explained in the configuration section.
Authentication and authorization
Current implementation of NGSIToPostgreSQL relies on the database, username and password credentials created at the
PostgreSQL endpoint.
About the persistence mode
Please observe not always the same number of attributes is notified; this depends on the subscription made to the
NGSI-like sender. This is not a problem for the row persistence mode, since fixed 8-fields data rows are inserted for
each notified attribute. Nevertheless, the column mode may be affected by several data rows of different lengths (in
term of fields). Thus, the column mode is only recommended if your subscription is designed for always sending the
same attributes, event if they were not updated since the last notification.
In addition, when running in column mode, due to the number of notified attributes (and therefore the number of fields
to be written within the Datastore) is unknown by Cygnus, the table can not be automatically created, and must be
provisioned previously to the Cygnus execution. That's not the case of the row mode since the number of fields to be
written is always constant, independently of the number of notified attributes.